
dfs는 이런식으로 풀더라
게시일:
OverView
백준을 시작한지가 어연 4개월은 넘은 것 같다. 평일이면 꾸준히 문제를 풀다보니 나름의 노하우가 생겼고, solved.ac 기준으로 플래티넘에 도달한 지금 정리도 할겸, 방법도 남길 겸 이렇게 시작을 하게 되엇다. dfs가 가장 먼저 선정한 주제인 이유는 그래프 문제를 많이 푼 까닭도 있지만, dfs보다는 bfs를 선호하는 까닭도 있다.
누군가를 위해 남기는 포스트가 아니기 때문에 figure가 존재하지 않지만 나에겐 도움이 되기에 이렇게 또 남긴다.
Depth First Search
dfs는 그 어원에서 알 수 잇듯이 깊이 우선 탐색이라는 의미를 지닌다. 사실 dfs를 이해하기 위해서는 그래프라는 용어에 대해서 이해하여야 된다.
Graph
알고리즘에서 그래프란 자료 구조인데 정점과 간선으로 이루어진 집합을 의미한다. 그래프는 사물 또는 추상적인 것들에 대한 연결 관계를 표시하는데 사용되는데 주로 도로망, 사람 관계 등에 대한 연결 구조를 표현할 때 주로 사용된다.
여기서 또 다시 정점과 간선이라는 용어가 등장하는데 정점(Vertex)는 주체가 되는 점들을 나타내며 간선(Edge)는 점들간에 연결된 상태를 나타내기 위해 사용된다. 정점과 정점을 이어주는데 간선이 되는 것이다. 좀 더 구체적인 예를 들자면 철수와 민희가 한 장소에 있고 그 둘은 연인 관계일 때 철수와 민희는 정점이 되고 연인이라는 키워드로 연관지은 그 관계는 간선이 되는 것이다.
근데 사실 위 예제에서 연인이라는 키워드로 정의된 관계 간선은 여러 형태를 띌 수 있다. 예컨대, 철수가 민희를 좋아하는 관계일수도, 그 반대일 수도, 서로 좋아하는 연인관계일수도 있다는 것이다. 즉 간선에 속성이 존재할 수 있다는 의미이다. 철수 -> 민희와 같이 한 정점에서 다른 한 정점으로만 성립하는 관계로 이루어진 그래프는 단방향 그래프라고 하고 철수 <-> 민희와 같이 쌍방의 관계를 가진 그래프를 양방향 그래프라고 한다. 양방향 그래프는 간선의 방향이 사실상 필요하지 않기에 무방향 그래프라고 표현하기도 한다.
또 하나의 중요한 개념으로는 가중치(Weight)가 있다. 바로 간선에 대하여 크기가 정의된 경우이다. 이는 위의 예제에서 철수와 민희가 가진 서로에 대한 호감도를 예로 들 수 있다. 호감도라는 수치를 가지고 있다는 간선(edge)는 호감도라는 가중치를 가지게 된다는 것이다. 알고리즘 문제를 풀다보면 가중치에 대한 문제가 많은데 한 도시로부터 다른 도시로 갈 때 이 가중치가 최소/최대 얼만큼이나 되는지에 대해 주로 물어본다. 이런 경우 한 정점으로부터 방향여부를 따라 순회하며 다른 한 정점으로 가는 경로에 대한 검증 및 최적화가 진행되어야 됨을 의미한다. 이런 과정에서 사용되는 알고리즘 중 하나가 DFS이고 이는 깊이를 우선으로 탐색하는 방식이다.
동작 원리
dfs는 그래프 상에 존재하는 모든 정점을 순회하는 방시그로 구현되는데 한 정점으로부터 인접한 간선들을 하나씩 확인하며 방문하지 않은 정점으로 향하는 간선이 존재하면 그 간선을 통해 다음 정점으로 이동하는 방법으로 구현된다. 만약 특정 한 정점에서 더 이상 간선을 통해 갈 수있는 새로운 정점이 존재하지 않는다면 새로운 정점을 찾는 것을 포기하고 정점으로 왔던 간선을 따라 되돌아가 다시 순회를 하게 된다. 역시나 말로 설명하면 무슨 말인지 모르겠다.
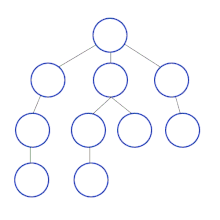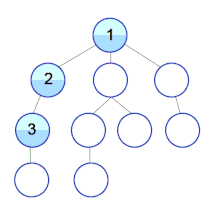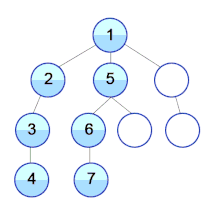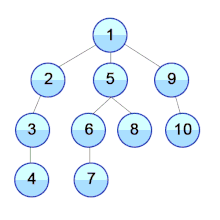
Wikipedia에서 예제를 하나 가져와 보았다. 1번 정점은 2,5,9 정점과 연결되어 있으며 2,5,9 정점은 다른 정점들과 각각 연결되어 있는 구조이다.
dfs는 깊이를 우선 탐색하기 때문에 한 정점을 통해 끝에 위치한 정점까지를 탐색한다. 1번 정점부터 탐색을 시작하면 간선을 통해 새로운 정점으로 이동하게 되는데 2,5,9와 연결되어 있으므로 한 정점으로 먼저 이동하게 된다. 그 정점이 해당 그래프에서는 2정점이고, 2정점은 3정점과 연결되어 있는 상태이다. 방문한 적이 없는 3정점을 간선을 통해 접근을 하게 되며 3정점을 통해 4정점까지 방문을 하게 된다. 4정점에 도달하게 되면 더 이상 간선을 통해 연결된 새로운 정점이 존재하지 않기 때문에 4정점으로 왔던 경로를 따라 되돌아가 3정점에 도달하게 되고 다시 3정점에서 2정점으로 돌아가고 출발지점이 1정점으로 마침내 되돌아오게 된다. 다시 돌아온 1정점은 5,9라는 방문하지 않은 새로운 정점으로 가는 간선을 가지고 있기 때문에 그 정점을 따라 순회를 하게 되고 5 -> 6 -> 7 -> 6으로 되돌아감 -> 5로 되돌아감 -> 8 -> 5로 되돌아감 -> 1로 되돌아감 -> 9 -> 10 -> 9로 되돌아감 -> 1로 되돌아감 -> 끝 과 같은 순서로 탐색을 진행하게 된다.
즉, 한 시작점을 기준으로 간선으로 연결된 모든 정점을 방문하되 깊이를 우선 탐색하기 때문에 방문한 정점을 기준으로 새로운 정점을 방문하는 과정을 진행하다 더 이상 갈 곳이 없을 경우 그 전 정점으로 돌아가 다른 정점을 찾는 방식으로 운영된다는 사실을 알 수 있다. 구현의 입장에서 이를 한 줄로 요약하면 정점을 기준으로 간선을 통해 갈 수 있는 새로운 정점이 없으면 그 전 정점으로 돌아간다고 말할 수 있다. 이를 위해서는 정점을 기준으로 새로운 정점을 찾아야 되며 다시 그 전 정점으로 돌아갈 수 있어야 하는데 이런 특성 때문에 재귀 형식으로 구현된다. 더 이상 방문할 곳이 없으면 return을 하는 방식으로 구현하게 되는 것이다.
구현
쉬운 문제 하나를 풀어서 구현을 해보도록 하자. ( 이 문제는 bfs가 더 효율적이겠지만 dfs로 풀어보도록 한다.. )
문제를 읽어보면 크기를 구해야 되는 문제라는 것을 알 수 있다. 상하좌우에 음식물이 위치하면 그 크기를 증가시키는 방식으로 진행하면 된다.
3 4 5
3 2
2 2
3 1
2 3
1 1
입력 값을 토대로 그려보면 다음과 같다.
# . . .
. # # .
# # . .
로직은 다음과 같다. dfs는 결국 한 정점을 토대로 방문 가능한 정점을 탐색하는 것에 목적이 있기 때문에 #으로 표시된 음식물이 위치하는 칸들을 시작 정점으로 dfs를 수행하면 되는데, (1,1)과 (2,2) 와 같이 연결이 되지 않은 부분도 존재하기 때문에 dfs를 모든 위치에 대해서 조건을 검사한 뒤 돌려야 될 필요성이 있다.
for(int i=1; i<=N; i++){
for(int j=1; j<=M; j++){
if(MAP[i][j] && !VISITED[i][j]){
maxv = max(maxv, dfs(i, j));
}
}
}
인접행렬의 각각의 칸들을 하나의 정점으로 생각하고 MAP[i][j]의 값을 검사한다. 만약 방문한 적이 없는 새로운 정점이면서 음식물이 위치한 경우에는 시작정점으로하는 dfs를 호출한다.
int dx[] = {0,0,-1,1};
int dy[] = {-1,1,0,0};
int dfs(int x, int y){
int val = 1;
VISITED[x][y] = true;
for(int i=0; i<4; i++){
int nx = x + dx[i];
int ny = y + dy[i];
if(nx<1 || ny<1 || nx>N || ny>M) continue;
if(MAP[nx][ny] && !VISITED[nx][ny]){
val += dfs(nx, ny);
}
}
return val;
}
dfs는 파라미터 값으로 행렬의 위치를 받아오는데 해당 위치를 기준으로 상,하,좌,우로 검사를 하여 방문하지 않은 음식물이 존재하는 정점이 있을 경우 다시 dfs를 재귀로 호출한다. 만약 상,하,좌,우 모두 방문을 하였거나 음식물이 아닌 경우에는 return을 하게 된다. 이렇게 순회하게 되면 (2,2) 지점을 기준으로 시작된 탐색이 (2,3) 정점을 방문하게 되고 그 곳에서부터 다시 탐색을 시작하게 된다. 이미 방문한 위치인 (2,2) 를 제외하고는 음식물이 존재하지 않기 떄문에 탐색이 중단되게 되고 다시 (2,2) 지점으로 돌아오게 된다. 그 후 다시 탐색이 재게되어 (3,2) 정점으로 이동하게 되고 (3,2) 정점에서는 (3,1) 정점으로 이동하게 된다. (3,1) 에서는 더 이상 새로운 정점으로 가는 길을 찾을 수 없으므로 다시 (3,2) -> (2,2)로 돌아가게 되고 탐색이 종료되게 된다.
// https://www.acmicpc.net/problem/1743
// 음식물 피하기
// Written in C++ langs
// 2020. 06. 22.
// Wizley
#include <iostream>
#include <algorithm>
using namespace std;
bool MAP[101][101];
bool VISITED[101][101];
int N, M, K;
int dx[] = {0,0,-1,1};
int dy[] = {-1,1,0,0};
int dfs(int x, int y){
int val = 1;
VISITED[x][y] = true;
for(int i=0; i<4; i++){
int nx = x + dx[i];
int ny = y + dy[i];
if(nx<1 || ny<1 || nx>N || ny>M) continue;
if(MAP[nx][ny] && !VISITED[nx][ny]){
val += dfs(nx, ny);
}
}
return val;
}
int main(){
ios_base :: sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
cin >> N >> M >> K;
int x,y;
for(int k=0; k<K; k++){
cin >> x >> y;
MAP[x][y] = true;
}
int maxv = 0;
for(int i=1; i<=N; i++){
for(int j=1; j<=M; j++){
if(MAP[i][j] && !VISITED[i][j]){
maxv = max(maxv, dfs(i, j));
}
}
}
cout << maxv << "\n";
}
장단점
dfs는 깊이 우선 탐색이기 때문에 현재 위치에 대한 정보만 가지고 있으면 재귀를 통해 탐색을 수행할 수 있으므로 저장공간을 아낄 수 있다. 또한 시작지점으로부터 깊이가 큰 곳에 해가 존재할 경우 빨리 구할 수 있다. 하지만 이는 동시에 잘못된 시작지점으로부터 탐색을 시작할 경우 끝도 없이 깊이 들어갈 수 있다는 문제가 동시에 존재하기도 한다. dfs자체가 깊이의 끝까지 탐색을 시도하기 때문에 비교적 깊이가 깊지 않은 곳에 해가 존재한다고 하더라도 잘못된 루트를 통해 탐색을 하게 되면 해를 찾는데 많은 시간이 소모된다는 것이다.
또 다른 단점으로는 최단경로를 보장하지 못한다는 것이다. 깊이를 우선 탐색하다보면 간선에 따라 하나의 정점에 가는 경로가 여러개 존재할 수 있다. 만약 조건이 도달가능성을 확인하는 경우라면 시간적인 손해를 보더라도 상관이 없지만 해당 경로로 가는 최단 거리를 찾아야 하는 경우에는 깊이를 우선으로 탐색한 경우에는 거리에는 최적의 해를 구할 수 없다.
이런 장단점 때문에 dfs는 깊이에 대한 정보가 명확하지 않은 경우에는 잘 사용되지 않는다. 극단적으로 그래프가 끝도 없는 깊이를 가지고 있다고 가정하면 알고리즘이 해를 찾을 수 없을 가능성뿐만 아니라 수없는 재귀호출로 인하여 스택이 터져버릴수도 있다. 이런 문제 때문에 백트래킹을 제외하고는 잘 사용하지 않는다.
시간복잡도
시간복잡도의 경우 인접행렬로 구현했느냐, 인접리스트로 구현했느냐에 따라 다르게 계산된다. 시간 복잡도 계산에서 정점(Vertex)의 개수는 V, 간선(Edge)의 개수는 E로 표현하겠다.
위의 문제는 인접행렬의 형식으로 풀이하였는데 dfs의 시작정점을 순회하는 횟수는 정점의 개수인 V만큼이다. 시작 정점을 기준으로 순회하며 다른 정점으로 이동할 수 있는 간선을 확인해야 되는데 이 또한 마찬가지로 V만큼의 복잡도를 가지게 되어 결국 O(V^2)가 된다.
void dfs(int vertex){
visited[vertex] = true;
for(auto dest : edge[vertex]){
if(!visited[dest]){
dfs(dest);
}
}
}
만약 위와 같이 인접리스트 형식으로 구현을 하게 된다면 시간복잡도는 어떻게 될까? 시작 정점으로 하는 정점의 개수는 마찬가지로 V개가 된다. 그리고 각각의 정점에 대해서 간선의 개수만큼 for문이 돌게 되므로 총 E만큼의 시간이 소모된다. 그러므로 O(V+E)를 시간복잡도로 가지게 된다. 결국 대략적인 시간복잡도는 O(정점의 개수 + 간선의 개수)라고 할 수 있다.